
Paper Digest: HPGR
Beyond the Flat Sequence: Hierarchical and Preference-Aware Generative Recommendations
💡 针对大模型在推荐系统中的“注意力失焦”问题,提出了 HPGR 两阶段生成框架。通过引入“层次化结构”与“偏好引导的稀疏注意力”,让 LLM 在超长用户历史中精准捕捉核心意图。
🚨 1. The Problem: 扁平序列的维度灾难
随着大语言模型(LLM)被引入推荐系统(Generative RecSys),业界普遍采用一种简单粗暴的做法:将用户的历史点击记录按时间拼接成一个极长的一维“扁平序列(Flat Sequence)”,直接喂给大模型。
核心痛点:信息噪音与 LLM 幻觉
真实的工业场景中,用户的行为是以 Session(会话)为单位的,具有强烈的层次化特征(如:早上看新闻,晚上看游戏)。强行将其扁平化,不仅破坏了行为的内部结构依赖,还会导致长序列中充斥着巨大的信息噪音。这使得 LLM 在推理时极易发生“分心(Distraction)”和“灾难性遗忘”,无法聚焦用户当下的真实意图。
真实的工业场景中,用户的行为是以 Session(会话)为单位的,具有强烈的层次化特征(如:早上看新闻,晚上看游戏)。强行将其扁平化,不仅破坏了行为的内部结构依赖,还会导致长序列中充斥着巨大的信息噪音。这使得 LLM 在推理时极易发生“分心(Distraction)”和“灾难性遗忘”,无法聚焦用户当下的真实意图。
🚀 2. The Breakthrough: HPGR 生成框架
为了重塑生成式推荐的信息输入流,我们提出了 HPGR (Hierarchical and Preference-Aware Generative Recommendation) 架构,将任务拆解为两步核心创新:
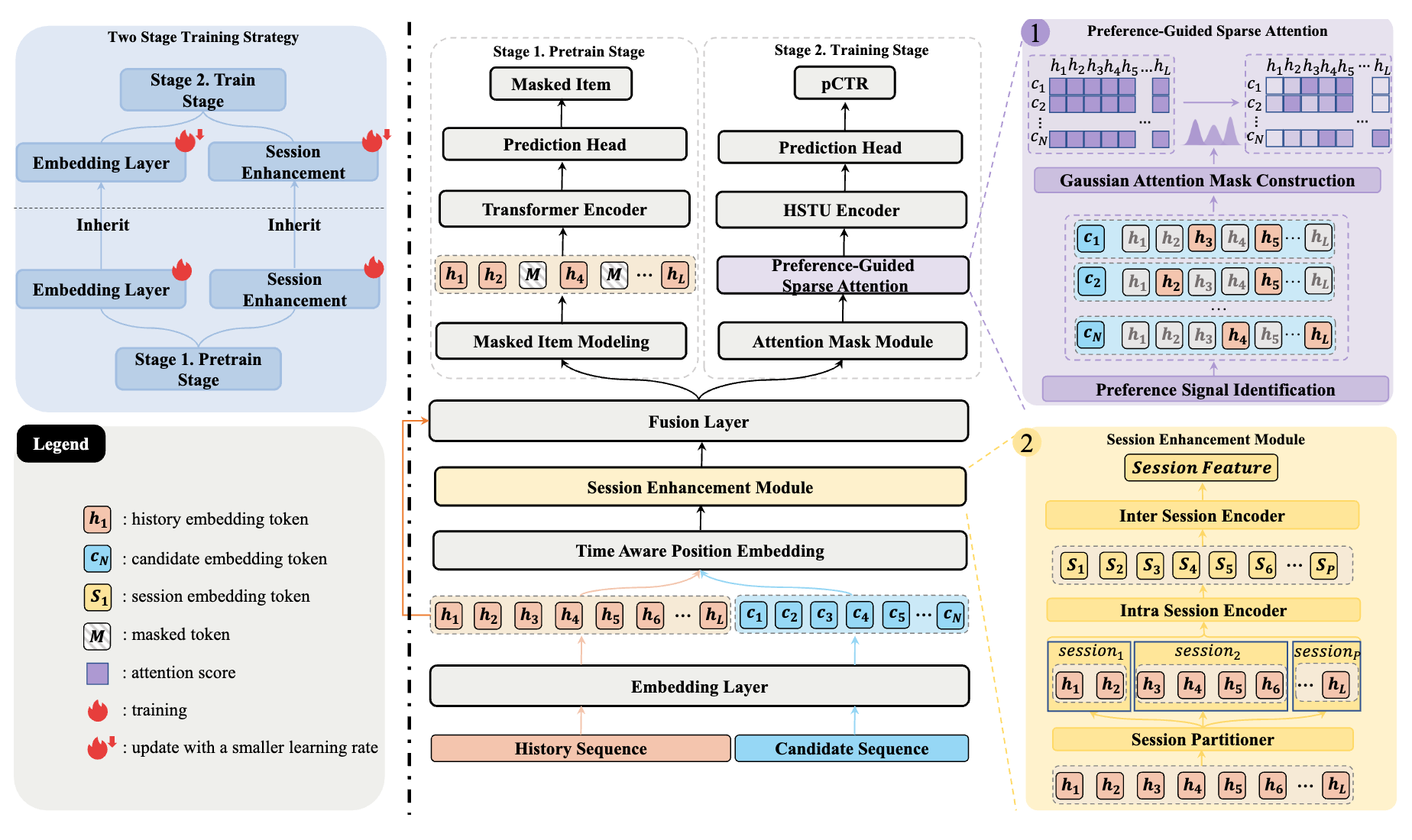
Figure: The HPGR framework, introducing hierarchical modeling to generative recommendations.
- 结构感知预训练 (Structure-Aware Pre-training): 我们放弃了单纯的从左到右的自回归训练,转而构建了一个层次化的行为树。通过特定的预训练任务,强迫 LLM 理解 Session 内部的紧密联系以及 Session 之间的宏观演进跳跃。
- 偏好引导的稀疏注意力 (Preference-Guided Sparse Attention): 在生成阶段(Decoding),我们打破了标准的全局注意力机制。模型会根据预判的用户当前偏好,动态过滤掉历史长河中的无关节点。这不仅去除了噪音,还极大地节省了算力开销。
📈 3. Key Results: 业务与实验价值
破局生成式推荐的长度限制:
HPGR 成功证明了,给 LLM 喂的数据“不是越长越好,而是越有结构越好”。
HPGR 成功证明了,给 LLM 喂的数据“不是越长越好,而是越有结构越好”。
在多个公开数据集上的实验表明,相比于现有的 TIGER 等平铺序列生成模型,HPGR 在各项推荐排序指标上均取得了显著 SOTA 收益。更重要的是,在处理超长历史序列(>100 个交互)时,传统模型性能断崖式下跌,而 HPGR 依然保持了极高的鲁棒性和意图命中率。
🔗 4. Resources
📄 Paper PDF: ACM Digital Library